Dam101_unit2
Data Preprocessing
What is DATA PREPROCESSING ?

Data preprocessing in machine learning is an important step that helps enhance the quality of data before feeding it into the model to extract meaningful output from the data.
Why Data Preprocessing?
Data preprocessing helps make the raw data cleaner and more meaningful so that the machine, to which we feed the data, understands our data and learns the patterns in it, allowing us to obtain the best output from the data.
Improve the data quality
Cleaning and refining raw data eliminates inaccuracies, missing values, and inconsistencies, ensuring that models are built on a clean and solid foundation.
Data preprocessing directly impacts the accuracy and conclusions drawn from the data. If the data is clean and well-organized, then the conclusions drawn will be more accurate.
Handling Missing Data
Missing values, as the term itself implies, refer to values that are absent in the dataset, which can occur due to technological failures or human errors during data recording.
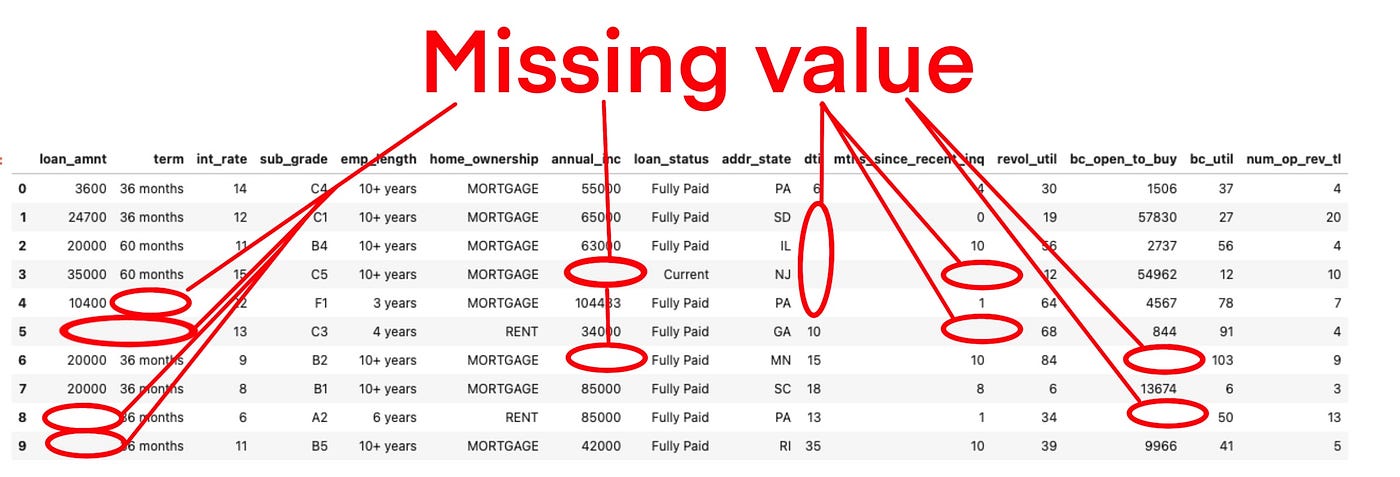
Missing values are handled using techniques such as imputation or removal of rows if the dataset is large. This ensures that analytical models are not skewed by the absence of crucial data points.
Standardizing and Normalizing
Standardizing and normalizing data during data preprocessing steps ensures consistency. It transforms diverse scales and units into a standardized format to enable fair comparisons and prevent certain features from dominating others.
Example :
We have a dataset containing two features: “age” and “income.” The “age” feature ranges from 0 to 100 years, while the “income” feature ranges from $2,000 to $200,000. Scaling these features so that they fall within a similar range, using methods like min-max scaling, allows us to scale the values between 0 and 1, making it more consistent for visualization and drawing conclusions.
Eliminating Duplicate Records
Duplicate entries can distort analyses and mislead decision-making processes moreover it will increase the run time resulting in more use of computational memory.
Data that are feed into the ML or Deep Learning Models are of different data type like :
- Numerical data
- Categorical data
- Tex data
- Image data
- Audio data
Each of the above data needs to be preprocessed differently according to there own recruitment
Introduction to image preprocessing.
Image preprocessing is the essential first step in teaching computers to understand pictures. In AI, it’s like cleaning and organizing images before the computer learns from them. This process is crucial because it helps the computer recognize patterns more effectively, like making sure all pictures are in the same format before learning.The clearer the data, the better the computer performs.
| Without Image Preprocessing | With Image Preprocessing |
|---|---|
| If you give these pictures directly to the computer, it might get confused. It may not understand that a small, dark cat is the same as a big, bright cat. It’s like trying to teach someone with blurry glasses; they might not see things clearly. | Now, imagine before teaching, you make all the pictures the same size, adjust the colors, and make sure they are not too bright or dark. This is like cleaning your glasses before learning. Image preprocessing helps the computer see things more clearly and understand, “Oh, all these pictures are cats, even if they look a bit different.” |

Challenges with raw data
Working with raw data presents lots of challenges for AI applications to make accurate predictions.
Noise and Distortions: Raw images often contain noise or distortions, impacting the model’s ability to discern meaningful patterns.
Color Spaces: Images can use various color representations (RGB, grayscale, etc.), requiring standardization for consistent analysis.
File Formats: Different formats (JPEG, PNG, etc.) can complicate data handling; standardization is crucial for seamless processing.
Large Datasets: High-resolution images or extensive datasets can strain computational resources during training.
Types of images.
- Grayscale image
In grayscale images, each pixel usually has a single intensity value ranging from 0 to 255 in an 8-bit image, where 0 represents black and 255 represents white.
In higher bit-depth images, such as 16-bit grayscale images, the pixel values can range from 0 to 65535.

- RGB image.
- In RGB (Red, Green, Blue) color space, each pixel is represented by three values corresponding to the intensity of red, green, and blue channels.
- In an 8-bit RGB image, each channel typically ranges from 0 to 255, resulting in a total of approximately 16.7 million possible colors (256^3).
In higher bit-depth RGB images, such as 16-bit or 32-bit per channel, the pixel values can range from 0 to 65535 or even higher.

- Floating point image
- In some cases, especially in scientific imaging or computer graphics, pixel values might be represented as floating-point numbers ranging from 0.0 to 1.0 or -1.0 to 1.0, where 0.0 represents black or absence of color and 1.0 represents white or maximum intensity.
Common image preprocessing technique.
- Re Scaling and NOrmalization
Pixel values represent image intensity. Scaling ensures these values fall within a specific range (usually 0 to 1 or -1 to 1), making computations more manageable and preventing dominance by large values.
Normalization adjusts pixel values to have a mean of 0 and a standard deviation of 1. It enhances model stability during training by keeping values within a standardized range, aiding convergence.

- Grayscale Conversion
- Converting an image to grayscale is like turning a colored picture into a black-and-white one.
- To convert a RGB image into grayscale, we take the average value of these three channels for each pixel.
- By converting to grayscale, we simplify the image and focus only on the brightness variations.
- We lose the color information, but sometimes that’s okay because it helps us focus on shapes, textures, and contrasts.
- Image Resizing and Cropping
- Resizing ensures all images in a dataset have consistent dimensions, facilitating model training. It prevents computational challenges and allows the model to learn patterns uniformly across different samples.
- Cropping focuses on specific regions of an image, excluding irrelevant details. This is valuable for tasks where the location of an object is essential, optimizing the model’s ability to recognize specific features
- Edge Detection
- Edge detection helps us find these borders or edges between objects or regions.
- Edges in an image occur where there’s a significant change in intensity or color.
- For example, the edge between a white wall and a black table is where the intensity changes abruptly.
- If you take a photo of a cat against a plain background, edge detection would help outline the shape of the cat